
In this edition of views from Academia I had the pleasure of talking to Professor Michael Wellman, Professor of Computer science & Engineering and Head of the Strategic Reasoning Group at the University of Michigan, about the exciting progress AI is making due to combining deep reinforcement learning with game-theoretic modelling. Below are some of the highlights.
Simon Grainger: For those of you that have missed Michael’s work on Game Theory and Agent-Based Modelling, can you give us a quick overview of the SRG?
Professor Michael Wellman: The Strategic Reason Group is part of the Artificial Intelligence Lab at the University of Michigan Computer Science Department.
"What we focus on is AI - automatic decision making in strategic domains".
What strategic means technically is that you're in a world where there are other agents and the outcome to you depends on their actions as well as your own. Your audience, of course, is extremely familiar with strategic domains. It's an everyday occurrence where we go into the market and you can't say what the best strategy is for us to play without thinking about how everyone else is going to react, what everyone else is going to do. That poses special challenges for AI because you're not just reasoning about the world but your reasoning about a special world where there are other entities that are also reasoning about the world, namely the other agents.
What we do is develop technology for this kind of decision making and it generally involves Game Theory, which is the fundamental science of predicting the behaviour of other rational agents, or “approximately” rational agents.

"If you believe that the other parties making decisions have a good basis for making those decisions, they may not be perfectly smart but they're probably as close to smart as you are. Then that's an appropriate tool to use".
Simon Grainger: Well it’s another topic whether the markets are rational or not. You gave a presentation recently on “Game Playing Meets Game Theory” referencing the AlphaGo project at Deep Mind and your own groups work on Empirical Game-Theoretic Analysis (EGTA). How excited are you by the potential of combining deep reinforcement learning with EGTA and why?
Professor Michael Wellman:
"This is a really exciting time for Artificial Intelligence. I've been working this field for a long time and the level of Interest has never been as great".
That's partly because of some breakthroughs that have recently come to pass and new applications that are getting a lot of attention. Some of these breakthroughs have been by groups like Google Deepmind on games like ‘Go’ and actually more recently ‘Starcraft’.

Game playing and AI have been together really since the beginning of AI with some of the first work on playing chess or checkers. AI has had milestones in game-playing over the past decades. IBM's Deep Blue beat Kasparov. That was really interesting and was kind of cool but it really didn't change AI much.
"No one really thought that the way that IBM beat Kasparov was going to be the technique with the key to AI. It might be different now".
The groups like Deepmind, Open AI and others are pursuing games as a challenging problem for AI not just arbitrarily because games are fun and people are interested in them because it's the multi-agent quality. The fact that you're pitting an intelligence against another intelligence, they view as a really effective way to drive AI because if you try to solve a problem that doesn't involve other agents usually with enough engineering you can eventually crack it, and then you're done.
But if there are other intelligent agents around, they're matching every step you take with a new idea that you have to respond to. The view in some of this really fundamental General AI work is that you need other agents to drive the development of intelligence further. So, I think that’s a really exciting new development.
Now, I mentioned my Strategic Reasoning Group because we're interested in Games, not necessarily because we want to solve the AI problem overall, but because we want to be good at games. I don't mean recreational games like ‘Go’ or ‘Poker’. They're kind of fun. But I mean games like trading in financial markets or games like cybersecurity.
"Real-world situations where there are other agents and being good at it has important consequences".
We've been following these developments with great interest. A really interesting twist and what was the impetus for the presentation you mentioned, was seeing that in a lot of the recent work out of Deepmind, and others, game-theoretic methods are playing a bigger role.
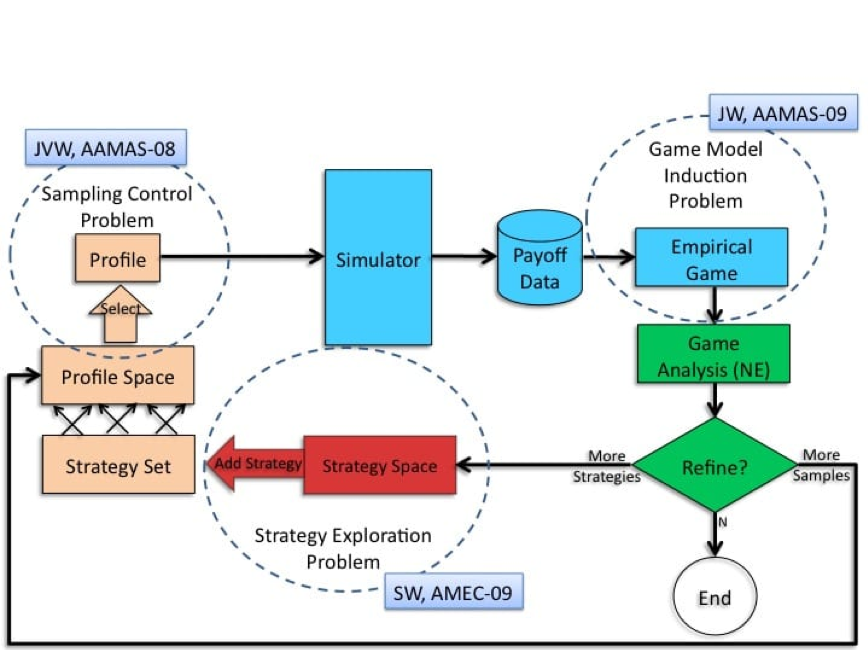
For example, they reached a significant milestone in the very complex video game Starcraft 2. They used game-theoretical methods to help decide which other agent strategies to focus on in their learning. A good strategy depends on anticipating what the others are going to do and it's a very large space. The techniques that they use are very similar to the Empirical Game Theoretical Analysis techniques that we've been using in our lab for solving real-world games. This is a way of combining agent-based simulation. Simulation modelling where you have entities called agents that are making decisions along the way with Game Theory.
Some of you may be familiar with building a game theory matrix. Real-world situations play out over time, have lots of uncertainty, maybe have many players and a lot of complex dynamics...
"...in those situations, we can’t even build the Matrix".
So we need more complex descriptions of the game situation and that's why we resort to agent-based simulation. We use the simulations to generate data about what happens when different combinations of strategies are played. Then we use this data with machine learning methods to learn a game model from that data.
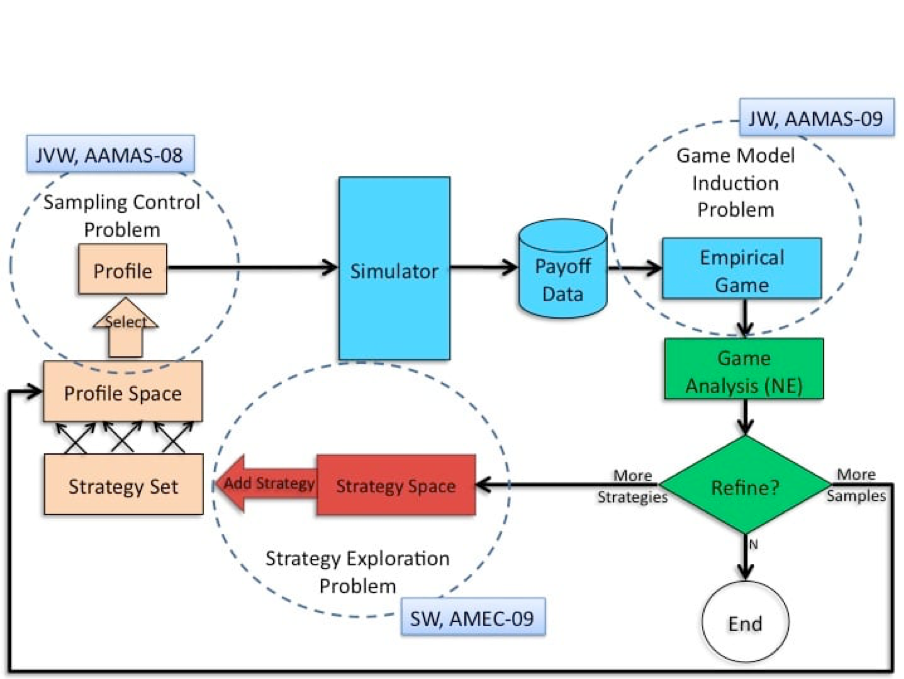
It's a combination of Game Theory, Agent-Based Simulation and Machine Learning. That's where the empirical in EGTA comes from, its using empirical methods like statistics and machine learning to do game reasoning. That's been the bread and butter technique that we've been applying to a lot of the domains of interest and we're also finding it’s really on the forefront of some of AI work pushing the envelope on games that can be solved.
Simon Grainger: Where does deep reinforcement learning come into this?
Professor Michael Wellman: Of course, deep learning in neural networks have been a big part of the recent resurgence of success in AI. Deep reinforcement learning is specifically the use of deep neural networks for learning policies, learning strategies to play in a complex environment including a game environment. Basically, you can think of deep RL as a technology for deriving a policy to respond to a situation and in a game or in a situation with other agents, that environment includes what the other agents do.
So in our EGTA methods, we have a step where we have to think of new strategies. We've tried a bunch of strategies. We understand the game among those strategies. Now, let's think of some additional strategies may be that we haven't evaluated yet.
"We use deep RL as a technique for generating those new strategies, and really that's how Alphago uses deep RL to come up with a new twist on a ‘Go’ playing strategy".
So, Deep RL is a technology for coming up with a new strategy, and we use it in conjunction with game theory as a kind of a strategy jet. It's a generator of strategy ideas which we can then evaluate using the game-theoretic methods.
Click here to view the entire interview and find out more about the practical domains that Michael is applying his research to or alternatively you can visit Michael at www.strategicreasoning.org and uncover a treasure trove of papers and resources dedicated to Game Theory and Agent-Based Modelling.
